我们现在考虑寻找以观测序列为条件的潜在变量的边缘概率分布的问题。在实时应用中,对于给定的参数设置,我们也希望以观测数据为条件,对于下一个潜在状态以及下一个观测做出预测。这些推断问题可以使用加-乘算法高效地解决,这个算法在线性动态系统的问题中会给出Kalman滤波方程和Kalman平滑方程。
值得强调的是,因为线性动态系统是线性高斯模型,因此所有潜在变量和观测变量上的联合概率分布是高斯分布,因此原则上我们可以使用之前章节推导的多元变量高斯分布的边缘概率 和条件概率的标准结果来解决这个推断问题。加-乘算法的作用是为这些计算提供了一个更加高效的方式。
线性动态系统与隐马尔可夫模型具有相同的分解方式,由公式(13.6)给出,并且由图13.14 和图13.15的因子图描述。于是,推断问题的形式完全相同,唯一的差别在于潜在变量上的求和被替换为积分。首先,我们考虑前向方程,其中我们将看做根结点,然后从叶结点将信息传递到根结点。根据式(13.77),初始信息服从高斯分布,并且由于每个因子都服从高斯分布,因此所有后续的信息也都服从高斯分布。按照传统,我们传递的信息是标准化的边缘概率分布,对应于,我们将其记作
这与式(13.59)给出的隐马尔科夫模型的离散变量情形的缩放变量的传播完全相同,因此递归方程的形式为
使用式(13.75)和(13.76)替换和,然后使用式(13.84),我们看到(13.85)变成了
这里我们假设和是已知的,并且通过计算式(13.86)中的积分,我们希望确定和的值。使用式(2.115)给出的结果,这个积分很容易计算。我们有
其中我们定义了
我们现在可以将这个结果与式(13.86)右侧的第一个因子结合,使用式(2.115)和(2.116),有
这里,我们使用了矩阵求逆的恒等式(C.5)和(C.7),并且定义了Kalman增益矩阵(Kalman gain matrix)
因此,给定和,以及新的观测,我们可以计算的高斯边缘分布,均值为,协方差为,标准化系数为。
这些递归方程的初始条件为
由于由式(13.77)给出,由式(13.76)给出,因此我们可以再次使用(2.115)计算,使用(2.116)计算和,结果为
其中
类似的,线性动态系统的似然函数由式(13.63)给出,其中因子使用Kalman滤波方程求解。
我们可以直观地给出从上的后验边缘分布到上的后验边缘分布的步骤,如下所述。在式(13.89)中,我们可以将看成上的均值的预测,得到这个预测的方法是在上取均值,然后使用一个前向的步骤,使用转移概率矩阵进行投影。预测均值会给出的一个预测观测,得到这个预测的方法是讲发射概率矩阵作用在预测的隐含状态均值上。我们可以将隐含变量分布的均值的更新方程(13.89)看成将预测分布的均值加上一个修正项,这个修正项正比于预测观测与实际观测之间的误差。 这个修正的系数由Kalman增益矩阵给出。因此我们可以将Kalman滤波的过程看成下面的过程:首先做出后续的预测,然后使用新的观测来修正这些预测。图13.21给出了图形说明。
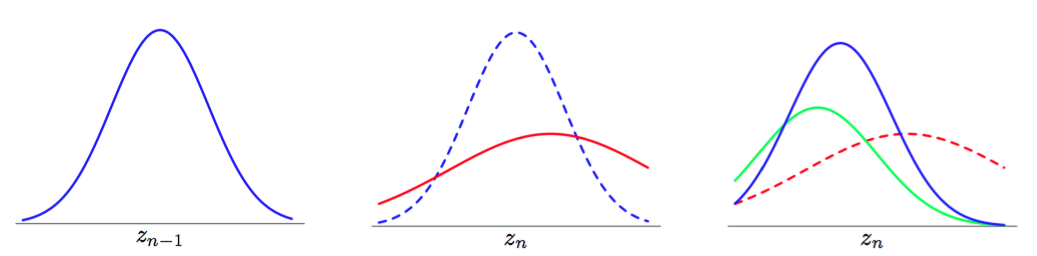
图 13.21 线性动态系统可以被看成一个步骤序列,其中由于传播造成的状态变量的逐渐增大的不确定性由新数据的到达所补偿。在左图中,蓝色曲线表示概率分布,它整合了截止到第步的所有的数据。由方差非零的转移概率产生的传播过程给出了概率分布,在中间图中表示为红色曲线。注意,与蓝色曲线相比,红色曲线更宽,并且有所偏移。为了对比,蓝色曲线用虚线画出。下一个数据观测通过发射概率密度产生贡献。右图中的绿色曲线表示发射概率与的函数关系。注意,它不是关于的概率密度,因此没有被归标准化。使用这个新的数据点会产生状态概率密度的一个修正的概率分布,用蓝色表示。我们看到,与相比,数据的观测使得概率分布产生偏移,并且变得更窄了。为了对比,在右图中用红色虚线表示。
如果我们考虑下面的情形:与潜在变量的变化速率相比,测量误差相对较小,那么我们看到zn的后验概率分布仅仅依赖于当前的测量xn,这与我们在本节开始时的简单例子中获得的直观感受相符。类似地,如果与观测的噪声水平相比,潜在变量的变化速度较慢,那么我们发 现zn的后验均值等于对截止到那个时间的所有测量求平均。
Kalman滤波的一个重要应用是跟踪。图13.22使用一个物体在二维空间移动的简单例子说明了这一点。
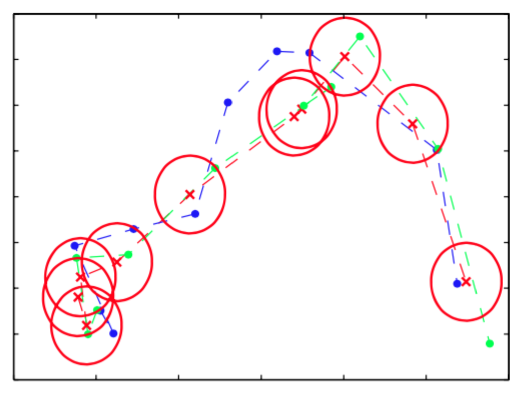
图 13.22 线性动态系统用于移动物体跟踪的一个说明。蓝点表示在连续的时刻,二维空间中物体的真实位置,绿点表示带有噪声的对位置的测量,红色叉号表示使用Kalman滤波方程推断出的后验概率分布的均值。推断位置的协方差由红色椭圆表示,它对应于一个标准差的轮廓线。
目前位置,我们已经解决了在给定到的观测的情况下寻找结点zn的后验边缘概率的问题。接下来,我们考虑在给定到的所有观测的条件下,寻找结点的边缘概率的问题。对于时序数据,这对应于将未来的观测以及过去的观测全部包含在内。虽然这无法用于实时预测,但是它在学习模型的参数中起着重要的作用。通过与隐马尔科夫模型的类比,这个问题可以这样求解:从结点将信息反向传递到结点,然后将这个信息与计算的前向信息传递阶段得到的信息相结合。
在LDS的文献中,通常根据表示后向递归公式,而是不根据。由于一定也是高斯分布,因此我们有
为了推导所求的递归方程,我们从的反向递归方程(13.62)开始,它对于连续潜在变量,可以写成
我们现在将(13.99)两侧乘以,使用式(13.75)和(13.76)消去和。然后,我们使用(13.89)、(13.90)和(13.91),以及(13.98),经过一些计算,我们有
其中我们定义了
并且我们使用了。注意,这些递归方程要求首先完成前向传递的过程,从而在后向过程中可以使用和。
对于EM算法,我们也需要求出一对变量的后验边缘分布,它可以通过公式(13.65)求出, 形式为
使用式(13.84)消去,整理,我们看到是一个高斯分布,均值为,和之间的协方差为