根据公式(2.8),可以得到伯努利分布中参数的最大似然解,因此在二项式分布中,最大似然解就是数据集中的观测所占的比例。正如我们之前提到的,对于小的数据集,这会发生非常严重过拟现象。为了以贝叶斯的观点来对待这样的问题,需要关于参数的先验分布。这里,我们考虑一种形式简单但很有用的先验分布。为了得到这个先验,注意到似然函数是一个因子乘以。如果选择一个正比于的幂的先验,那么我们的后验就正比于先验和似然函数的乘积,且与先验分布具有相同的函数形式。这种性质被称为共轭(conjugacy),在本章的后面会看到几个这样的例子。因此,选择Beta分布为我们的先验分布:
其中
(2.13)中的系数保证beta分布是标准的,所以:
其中均值和方差:
由于控制了分布的参数,所以一般被称为超参数(hyperparameters)。图2.2展示了不同的超参数的beta分布。
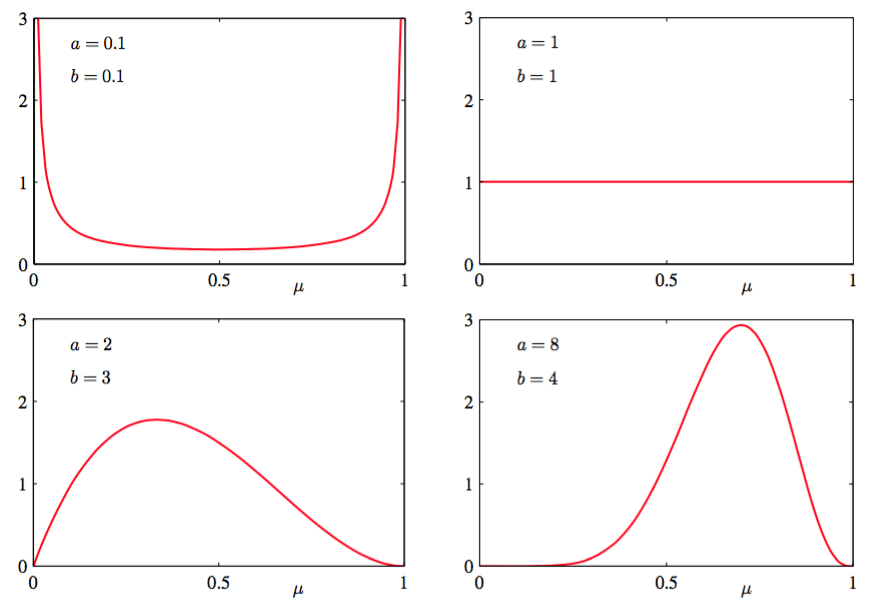
图 2.2 beta分布
现在,把Beta先验(2.13)与二项似然函数(2.9)相乘再标准化就得到了的后验分布。只保留依赖的因子,得到后验分布的形式:
其中,即硬币例子中对应的反面朝上的数量。我们看到公式(2.17)依赖于的函数形式与先验分布相同,这反映了先验关于似然函数的共轭性质。事实上,这仅仅是另一种形式的Beta分布,对比公式(2.13)可以得到标准化系数:
从先验概率到后验概率,我们把数据集中个的观测值增加了,个的观测值增加了。这使我们可以简单的把先验概率中的超参数和分别解释为的有效观测数(effective number of observation)。注意不一定是整数。此外,如果接下来我们观测更多数据,那么就可以把后验分布当成先验分布。为了说明这一点,我们可以想象每次只取一个观测值,然后在每次观测之后乘以新观测值的似然函数,再标准化来更新当前的后验分布。在每个步骤中,后验是的观测总数(先验的和实际的)的beta分布。新的的观测值对应的把的值增加1,而新的的观测值对应的把的值增加1。图2.3展示了其中一步。
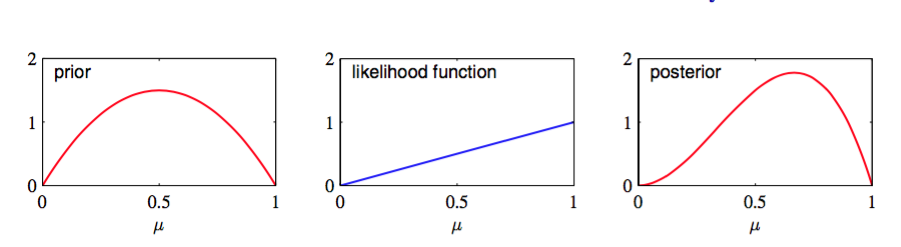
图 2.3 贝叶斯顺序推断中的一个步骤
如果采用贝叶斯观点,这个顺序方法就自然产生了。这不依赖于先验或似然函数的选择,只取决于数据是否独立同分布的。顺序方法每次使用一个或一小批观测值,然后在使用下一观测值之前丢掉它们。这可以在一个稳定的数据流持续到达,模型必须在观测到所有数据之前就进行预测,这样的实时学习场景下使用。由于它不需要所有的数据都存储或加载到内存中,顺序方法在大数据中也非常有用。最大似然方法也可以转化成顺序框架。
如果我们的目标是尽可能准确的预测下一次试验的输出,我们必须在给定观测数据集的情况下,评估的预测分布。根据概率的加法和乘法规则,可以得到:
对后验分布应用公式(2.18),beta分布的均值应用公式(2.15),得到:
这个结果可以简单的解释为对应于的观测结果(包括实际的观测值和假想的先验观测值)所占的比例。注意,在数据集无限大的极限情况下,此时公式(2.20)的结果变成了最大似然的结果(2.8)。正如我们将看到的那样,贝叶斯的结果和最大似然的结果在数据集的规模趋于无穷的情况下会统一到一起。对于一个有限的数据集,的后验均值,通常位于先验均值和公式(2.7)给出的的最大似然估计之间。
根据图2.2得到,当观测数量增加时,后验分布的图像变得更尖了。这也可以从公式(2.16)中beta分布的方差得到,当或时方差趋向于0。事实上,我们可能想知道:随着我们观测到越来越多的数据,后验概率表示的不确定性将会持续下降。这个性质是贝叶斯学习的一个共有属性。
为了证明这点,可以通过频率学观点来观察贝叶斯学习。一般来说这种性质确实成立。考虑一个观测数据集,参数为的贝叶斯推断问题,有联合分布描述,结果:
其中
的后验均值(在产生数据集的分布上的平均)等于的先验均值。同样的我们可以得到:
公式(2.24)中左手边的项是的先验方差。右手边的第一项是的后验方差的均值。第二项是的后验均值的方差。因为方差是一个正的量,所以一般来说,的后验方差小于先验方差。后验均值的方差越大,这个差值的就越大。注意,这个结果只在通常情况下成立,对于特定的观测数据集,后验方差有可能大于先验方差。