在2.3.9节,我们将高斯混合模型看成高斯分量的简单线性叠加,目标是提供一类比单独的高斯分布更强大的概率模型。我们现在使用离散潜在变量来描述高斯混合模型。这会让我们更深刻地认识这个重要的分布,也会让我们开始了解期望最大化算法。
回忆一下,根据式(2.188),高斯混合概率分布可以写成高斯分布的线性叠加的形式,即
让我们引入一个为二值随机变量,这个变量采用了“1-of-K”表示方法,其中一个特定的元素等于1,其余所有的元素等于。于是的值满足且,并且我们看到根据哪个元素非零,向量有个可能的状态。我们根据边缘概率分布和条件概率分布定义联合概率分布,对应于图9.4所示的图模型。
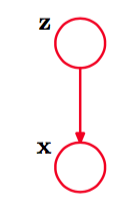
图 9.4 混合模型的图形表示,其中联合概率分布被表示为的形式。
的边缘概率分布根据混合系数进行赋值,即
其中参数必须满足
以及
使得概率是一个合法的值。由于使用了“1-of-K”表示方法,因此我们也可以将这个概率分布写成
类似地,给定的一个特定的值,的条件概率分布是一个高斯分布
也可以写成
联合概率分布为,从而的边缘概率分布可以通过将联合概率分布对所有可能的求和的方式得到,即
其中我们使用了式(9.10)和式(9.11)。因此的边缘分布是式(9.7)的高斯混合分布。如果我们有若干个观测,那么,由于我们已经用的方式表示了边缘概率分布,因此对于每个观测数据点,存在一个对应的潜在变量。
于是,我们找到了高斯混合分布的一个等价的公式,将潜在变量显式地写出。似乎我们这么做没有什么意义。但是,我们现在能够对联合概率分布操作,而不是对边缘分布操作,这会产生极大的计算上的简化。通过引入期望最大化(EM)算法,即可看到这一点。
另一个起着重要作用的量是给定的条件下,的条件概率。我们会用表示,它的值可以使用贝叶斯定理求出
我们将看成的先验概率,将看成观测到之后,对应的后验概率。正如我们将看到的那样,也可以被看做分量对于“解释”观测值x的“责任”(responsibility)。
我们可以使用祖先取样的方法生成服从高斯混合模型的概率分布的随机样本。为了完成这件事,我们首先生成的一个值,记作,它服从概率分布。然后,根据条件概率分布生成的一个值。从标准的概率分布中取样的方法将在第11章讨论。我们可以用下面的方法描绘联合概率分布:首先画出的对应值的点,然后根据的值对它进行着色,换句话说,根据哪个高斯分布负责生成这个数据进行着色,如图9.5(a)所示。

图 9.5 从图2.23给出的3个高斯分布组成的混合分布中抽取的500个样本点。(a)从联合概率分布中抽取的样本,其中的三种状态对应于混合分布的三个分量,用红色、绿色、蓝色表示。(b)来自边缘概率分布的对应的样本,仅仅将z的值忽略,画出的值即可。(a)中的数据集被称为
完整的,(b)中的数据集被称为不完整的。(c)同样的样本,颜色表示与数据点关联的责任,其中红色、蓝色、绿色所占的比重分别由给出。
类似地,服从边缘概率分布的样本可以通过从联合概率分布中取样然后忽略z的值的方式得到。这些如图9.5(b) 所示。图中画出了的值,没有任何颜色标记。
我们也可以使用这个人工生成的数据来说明“责任”的含义。对于每个数据点,我们计算生成了数据集的混合概率分布的每个分量的后验概率分布。特别地,我们可以表示出与数据点xn相关联的责任的值,方法是:对于,我们分别用红色、蓝色、绿色来画出对应的点,点的颜色的红蓝绿分量的比例由给出,如图9.5(c)所示。因此,的数据点会被标记为红色,而的数据点的颜色中,蓝色和绿色的比例相同,因此是青色。应该将这幅图与图9.5(a)进行对比,那里数据点使用它们被生成的真实的分量类别进行了标记。