分类的高斯过程的第三种方法是,现在我们要详细讨论的,基于拉普拉斯近似的。为了计算预测分布(6.76),我们寻找的后验分布的高斯近似,它由
其中,我们使用了。条件分布是通过式(6.66)和式(6.67)给出的高斯过程回归,来给出的:
于是,通过找到后验概率分布的拉普拉斯近似,然后使用两个高斯分布卷积的标准结果,我们就可以计算式(6.77)中的积分。
先验概率由一个均值为0,协方差矩阵为,数据项(假设数据点之间具有独立性)由
高斯过程给出。然后通过对的对数进行泰勒展开,得到拉普拉斯近似。忽略掉一些可加的常数,这个概率对数为:
首先我们需要找到后验概率分布的众数,这需要我们计算的梯度。这个梯度为
其中是一个元素为的向量。寻找众数时,因为的关系是非线性的,所以我们不能简单地令这个梯度等于0,因此我们需要使用基于Newton-Raphson方法的迭代的方法,它给出了一个迭代重加权最小平方(IRLS)算法。这需要求出的二阶导数,而这个二阶导数也需要进行拉普拉斯近似,结果为
其中是一个对角矩阵,元素为,并且使用了式(4.88)给出的logistic sigmoid函数的导数的结果。注意,这些对角矩阵元素位于区间,因此是一个正定矩阵。由于(以及它的逆矩阵)被构造为正定的,并且由于两个正定矩阵的和仍然是正定矩阵,因此我们看到Hessian矩阵是正定的,因此后验概率分布是对数凸函数,因此有一个唯一的众数,即全局最大值。然而,因为Hessian矩阵是的函数,所以后验概率不是高斯分布。
使用Newton-Raphson式(4.92),的迭代更新方程为
这个方程反复迭代,直到收敛于众数(记作)。在这个众数位置,梯度为0,因此满足
一旦我们找到了后验概率的众数,我们就可以计算Hessian矩阵,结果为
其中的元素使用计算。这定义了我们对后验概率分布的高斯近似,结果为
我们现在可以将这个结果与式(6.78)结合,然后计算积分(6.77)。因为这对应于线性高斯模型,我们可以使用一般的结果(2.115)得到
现在我们有一个的高斯分布,我们可以使用式(4.153)的近似积分(6.76)。与4.5节的贝叶斯logistic回归模型相同,如果我们只对对应于的决策边界感兴趣,那么我们只需考虑均值,可以忽略方差的效果。
我们还需要确定协方差函数的参数。一种方法是最大化似然函数,此时我们需要对数似然函数和它的梯度的表达式。如果必要的话,还可以加上正则化项,产生一个正则化的最大似然解。最大似然函数的定义为
这个积分没有解析解,所以我们需要再次使用拉普拉斯近似。使用式(4.135)的结果,我们得到了下面的对数似然函数的近似
其中。我们还需要计算关于参数向量梯度。注意,的改变会造成的改变,产生梯度中的附加项。因此,当我们对(6.90)关于求积分时,我们得到了两个项的集合,第一个集合产生于协方差矩阵对的依赖关系,第二个集合产生于对的依赖关系。
显式地依赖于的项可以使用式(6.80)以及式(C.21)(C.22)给出的结果得到:
为了计算由于对的依赖产生的项,我们注意到我们已经构造了拉普拉斯近似,从而在处,的均值为0,所以对于梯度没有贡献。剩下的有贡献的项关于的分量的导数为
其中,且又一次使用了式(C.22)给出的结果及的定义。我们可以将式(6.84)给出的关系关于求积分,得到关于的导数:
整理,可得
结合公式(6.91)、(6.92)和(6.94),我们可以计算对数似然函数的梯度,然后使用标准非线性优化算法来确定的值。
我们可以使用人工生成的两类数据来说明拉普拉斯近似对于高斯过程的应用,如图6.12 所示。
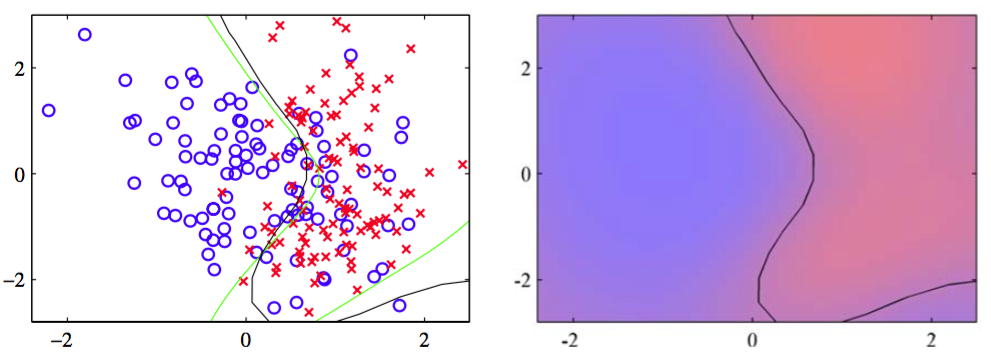
图 6.5 使用高斯过程进行分类的说明。左图给出了数据点,以及来自真实概率分布的最优决策边界(绿色),还有来自高斯过程分类器的决策边界(黑色)。右图给出了蓝色类别和红色类别的预测后验概率分布,以及高斯过程决策边界。
很容易将拉普拉斯近似推广到涉及个类别的使用softmax激活函数的高斯过程 (Williams and Barber, 1998)。