我们已经把分类问题分成了隔开的两个阶段:使用训练数据学习的模型的推断阶段(inference stage),和随后的使用这些后验概率来对类别作最优的分类的决策阶段(decision stage)。另一种可能是简单的学习一个函数来把输入直接映射成决策,来同时解决这两个问题。这样的函数被称为判别函数(discriminant function)。
事实上,我们有三种不同的方法来解决决策问题,它们都已经在实际问题中使用。下面按复杂度降低的顺序给出这三种方法:
(a)首先,通过对每个类别,独立的确定类别的条件密度来解决推断问题,还分别推断出类别的先验概率,然后使用贝叶斯定理:
来计算类别的后验概率。因为 所以通常,贝叶斯定理的分母可以用分子中出现的项表示。同样的,可以直接对联合分布建模,然后标准化后得到后验概率。得到后验概率后,使用决策论来确定每个新的输入的类别。因为可以通过取样来合成输入空间的数据点,所以显式或隐式的对输入和输出进行建模的方法被称为生成模型(generative models)。
(b)首先,解决确定类别的后验密度的推断问题,然后,使用决策论来对新的输入进行分类。这种直接对后验概率建模的方法被称为判别模型(discriminative models)。
(c)找到能直接把输入映射到类别标签的判别函数(discriminant function)。例如:在,是二元分类问题中一个二元的数值,表示类别,表示类别。这种情况下,概率不起作用。
现在讨论一下这三种方法的优缺点。方法(a)是最严格的,因为它涉及找到的联合分布。对于大多数应用,的维度很高,这导致需要大量的训练数据才有可能以合适的精度来确定类别的条件密度。注意,类别的先验可以根据训练数据集里的每个类别的数据点各自所占的比例简单的估计出来。方法(a)的一个优点是,它能够通过公式(1.83)求出数据的边缘概率密度。这对那些由于低概率导致的预测准确率可能会很低的新数据点会很有用。这种技术被称为离群点检测(outlier detection)或新奇点检测(novelty detection)(Bishop, 1994; Tarassenko, 1995)。
如果只想进行分类的决策,那么这种方法很浪费计算资源。为了计算联合分布我们需要大量的数据,而实际上我们只需要使用方法(b)就能直接求出的后验概率。实际上,类别条件密度可能包含很多对后验概率几乎没有影响的结构,如图1.27所示。
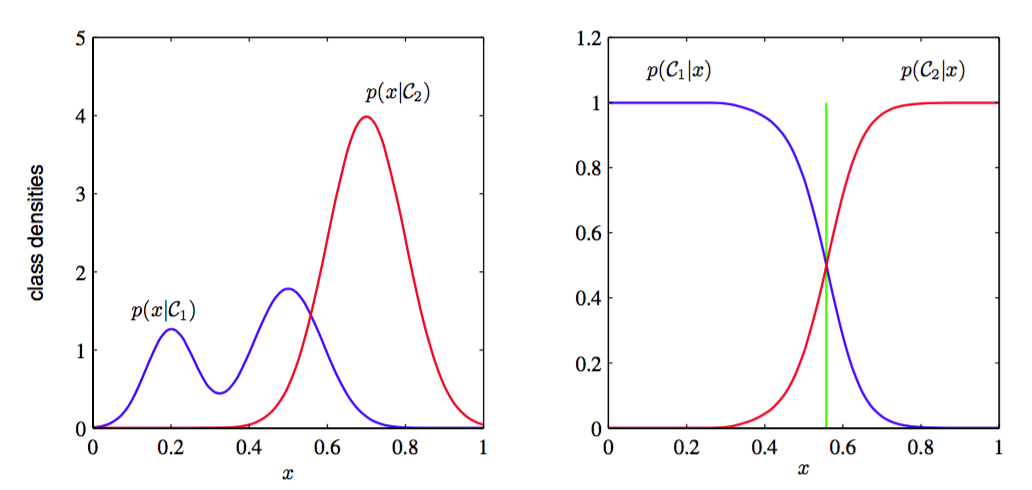
图 1.27: 具有一元输入变量的两个类别的类条件概率密度(左图)以及对应的后验概率密度(右图)。 注意,左图中,蓝色曲线表示类条件概率密度,它的峰值对于后验概率分布没有影响。右图中的垂直绿色直线表示给出最小误分类率的的决策边界。我们假设先验概率分布和是相等的。
机器学习中的生成式方法和判别式方法的相对优势,以及如何将两者结合,有很多有趣的研究成果(Jebara, 2004; Lasserre et al., 2006)。
在更简单的方法(c)中使用训练数据来寻找将每个直接映射为类别标签的判别函数,从而把推断与决策步骤结合到单个的学习问题中。在图1.27的例子中,他与绿色竖直线给出的的值对应,因为这是得到最小误分率的决策边界。
使用方法(c),我们就再也不能得到后验概率。但是,有很多强烈的理由需要计算后验概率来帮助我们进行接下来的决策。包括:
最小化风险
考虑损失矩阵的元素时时刻刻都被修改的问题(金融应用中可能出现的情况)。如果我们知道后验概率,我们只需要恰当的修改公式(1.81)所定义的最小风险决策准则即可。如果我们只有一个判别准则,那么损失矩阵的任何改变都需要我们返回重新训练数据,来解决分类问题。
拒绝选项
如果给定被拒绝的数据点所占的比例,后验概率让我们能够确定最小化误分类率的拒绝标准,或者更一般的,确定在给定拒绝点比例的情况下的损失期望。
补偿类别先验概率
再次考虑我们的医疗X光片问题,假设已经从普通人群中收集了大量的X光片,作为建立自动诊断系统的训练数据。由于癌症在普通人群中是很少见,我们可能发现1000个样本中只有一个患有癌症。如果使用这样的数据来训练自适应的模型,由于癌症类的比例很小,我们会遇到严重的困难。例如,一个将所有的点都判定为正常类的分类器就已经能够达到99.9%的精度,避免这样的无用解是很困难的。同样的,即使训练数据很大,其中癌症的X光片的样本数量还是很少的,因此学习算法不会接触到广泛的样本,所以它的泛化能力也不会很好。一个平衡的数据集中,每个类别都选择了相等数量的样本,这让我们能够训练出一个更加准确的模型。然而,之后就必须补偿修改训练数据所造成的影响。假设已经使用这种修改后的数据,得到了后验概率的模型。根据公式(1.82)的贝叶斯定理,后验概率正比于先验概率,而先验概率可以表示为各个类别的数据点所占的比例。因此我们可以用从人造的平衡数据中得到的后验概率除以数据集里的类别比例,再乘以想要应用模型的目标人群中类别的比例即可。最后,我们需要进行标准化来保证新的后验概率之和等于1。注意,如果直接学习一个判别函数而不确定后验概率,这个步骤是无法进行。
组合模型
对于复杂的应用,我们想把问题分解成一些可以单独解决的子问题。例如:在我们假设的医学诊断的问题中,来自血液检测的信息和X光片同样重要。这两个模型都会给出各自的类别后验概率,可以使用概率论的规则来把它们结合在一起。一种简单方法是:X光片的输入分布记为,血液数据记为,它们是独立的,所以可得:
因为这是条件上的分布是独立的,所以这是条件独立性(conditional independence property)的一个例子。于是得到X光片和血液给出的后验概率为:
通过估计每个类别的数据点所占的比例,就可以很容易地得到我们需要的类别先验概率。然后对后验概率标准化,使得后验概率之和等于1。公式(1.84)的独立性假设是朴素贝叶斯模型(naive Bayes model)的一个例子。注意,在这个模型下,通常不会分解联合边缘分布。在后续章节中,我们会看到如何不依赖公式(1.84)的独立性假设来建立组合数据的模型。