遵从Minka(2001b)的做法,我们使用一个简单的例子来说明EP算法,其中我们的目标是在给定服从那个分布的一组观测的情况下,推断变量上的多元高斯分布的均值。为了让问题更加有趣,观测位于一个背景杂波中,它本身也是一个高斯分布,如图10.15所示。
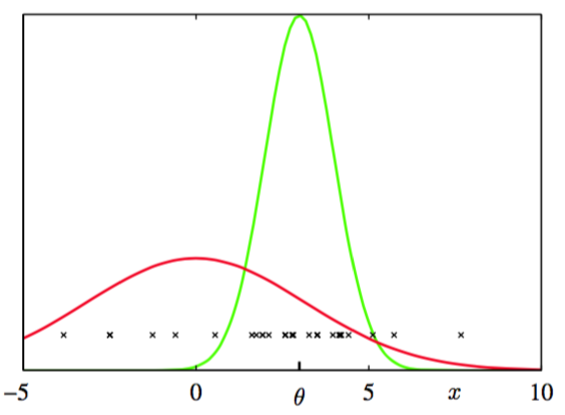
图 10.15 维度为的数据空间中的聚类问题的说明。训练数据点(用叉号表示),从两个高斯分布混合而成的分布中抽出,高斯分量用红色和蓝色表示。我们的目标是从观测数据中推断绿色高斯分布的均值。
于是,观测值的概率分布是一个混合高斯分布,形式为
其中,是背景杂波的比重,假设是已知的。上的先验概率分布是高斯分布,形式为
Minka(2001a)选择参数的值为。次观测和的联合概率分布为
因此后验概率分布由个高斯分布混合而成。从而精确解决这个问题的计算代价会随着数据集的规模指数增长,因此对于大的值,精确求解是不可行的。
为了将EP应用于杂波问题,我们首先看出,因子且。接下来,我们从指数族分布中选择一个近似分布。对于这个例子,比较方便的做法是选择一个球形高斯分布
于是,因子近似会取指数-二次函数的形式,即
其中,且令等于先验概率分布。注意,使用不表示右手边是一个良好定义的高斯概率密度(事实上,正如我们将看到的那样,方差参数可以为负),而是仅仅是一个方便的简化记号。近似可以被初始化为1,对应于以及,其中是的维度,因此也是的维度。式(10.191)定义的初始的因此就等于先验概率分布。
我们接下来迭代的优化因子,方法是每次取一个因子,然后使用式(10.205)、(10.206)和(10.207)。注意,我们不需要修改,因为EP更新会让这一项保持不变。这里,我们给出结果,让读者自己来填充细节。
接下来,我们使用式(10.206)计算标准化常数,结果为
类似的,我们通过寻找的均值,计算的均值和方差,结果为
其中
它可以简单的表示为点不在杂波中的概率。然后,我们使用式(10.207)计算优化因子,它的参数为
优化过程不断重复,直到满足一个合适的终止准则,例如在对所有因子进行的一次优化迭代中,参数值的最大改变量小于一个阈值。最后,我们使用式(10.208)来计算模型证据的近似,结果为
其中
图10.16给出了对于一维参数空间的杂波问题的因子近似的例子。
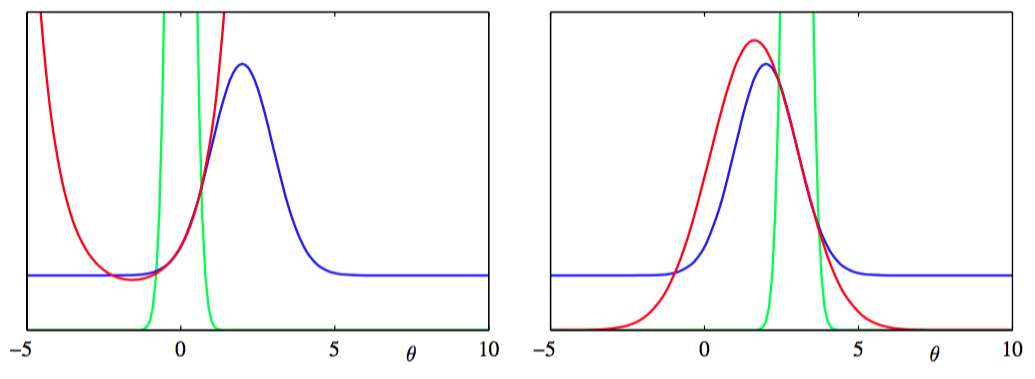
图 10.16 对于杂波问题的一维版本,具体因子的近似的例子。图中用蓝色表示,用红色表示,用绿色表示。注意现在的形式控制了的取值范围,在这个范围上,是的一个很好的近似。
注意,因子近似可以有无穷大的或者负数的“方差”参数。这仅仅对应于曲线向上弯曲而不是向下弯曲的情形,并且只要所有的近似后验概率有正的方差,这种情形就未必有问题。图10.17对比了在杂波问题中,EP的表现、变分贝叶斯(平均场理论)的表现以及拉普拉斯近似的表现。
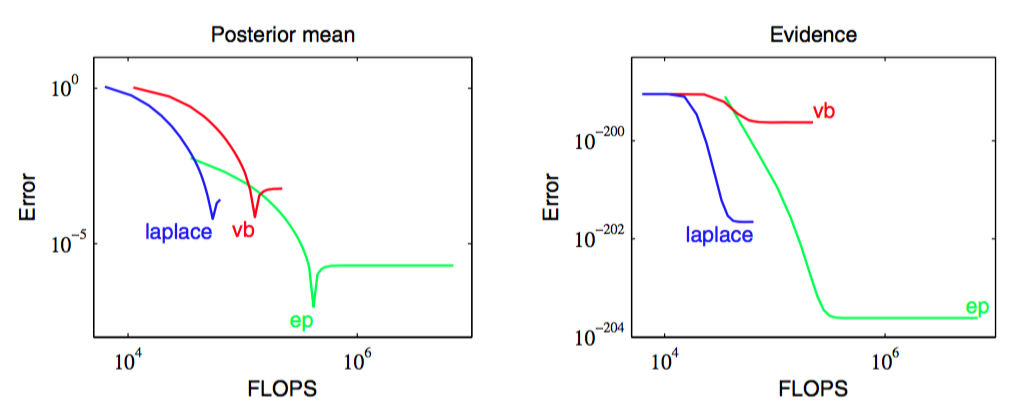
图 10.17 期望传播、变分推断和拉普拉斯近似在聚类问题上的对比。左图给出了预测后验概率分布的均值与浮点运算的数量的关系,右图给出了对应的模型证据的结果。