目前为止,我们已经介绍了信息论的许多概念,包括熵的关键思想。我们现在开始把这些思想关联到模式识别的问题中。考虑某个未知的分布,假定我们已经使用一个近似的分布对它进行了建模。如果我们使用来建立一个编码体系,用来把的值传给接收者,那么,由于我们使用了而不是真实分布,因此在具体化的值(假定我们选择了一个高效的编码系统)时,需要一些附加的信息。需要的平均的附加信息量(单位是nat)为:
这被称为分布和分布之间的相对熵(relative entropy) 或者Kullback-Leibler散度 (Kullback-Leibler divergence),或者KL散度(Kullback and Leibler, 1951)。注意这不是一个对称量,即。
现在要证明,Kullback-Leibler散度满足,并且当且仅当时等号成立。为了证明这一点,我们首先介绍凸函数(convex function)的概念。如果一个函数具有如下性质:每条弦都位于函数图像或其上方(如图1.31所示),那么我们说这个函数是凸函数。
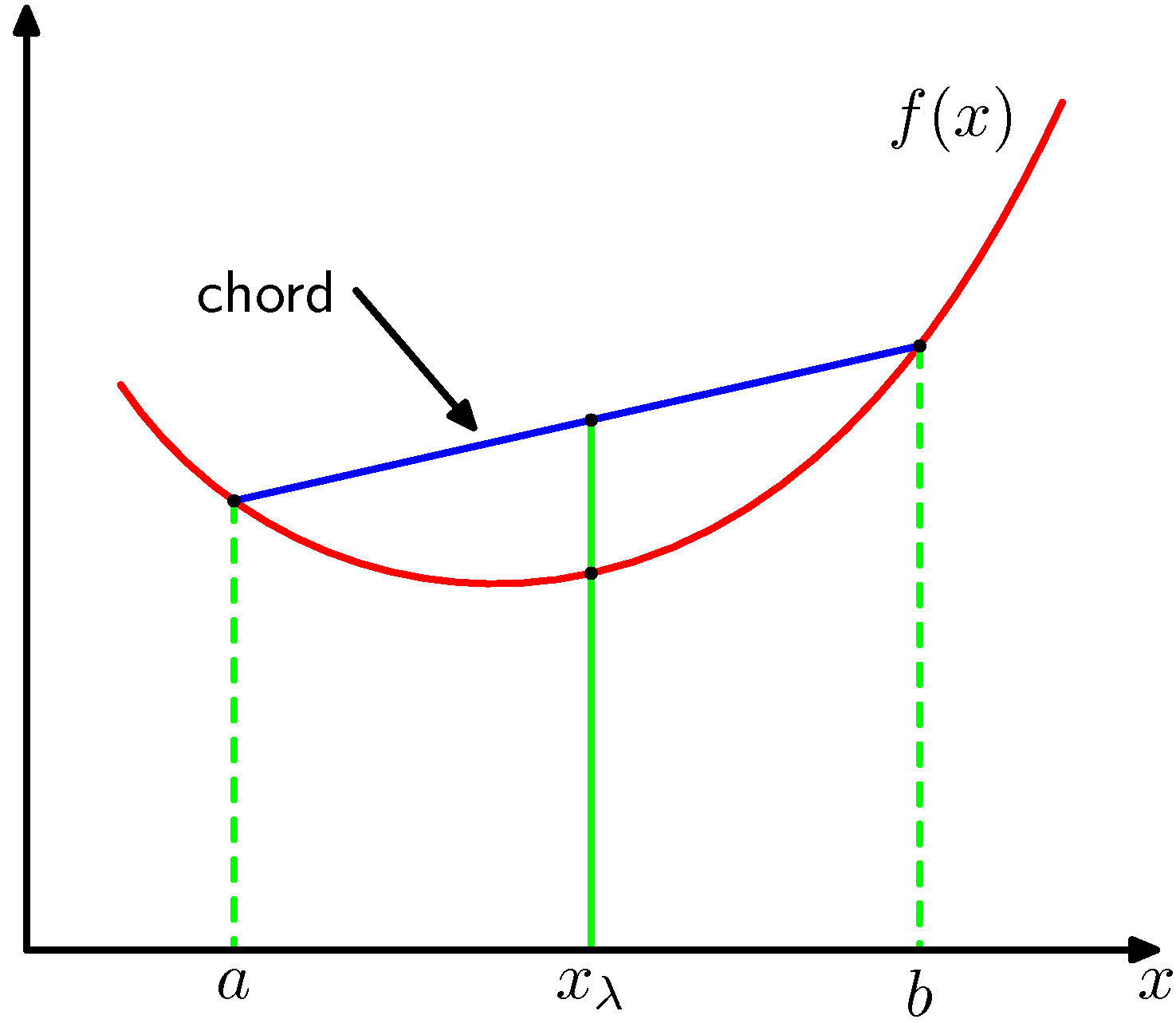
图 1.31 凸函数的每条弦(蓝色表示)位于函数上或函数上方,函数用红色曲线表示。
位于到之间的任何一个值都可以写成的形式,其中。弦上的对应点可以写成,函数的对应值为。这样,凸函数的性质就可以表示为
这等价于要求函数的二阶导数处处为正。凸函数的例子有和。如果等号只在和处取得,我们就说这个函数是严格凸函数(strictly convex function)。如果一个函数具有相反的性质,即每条弦都位于函数图像或其下方,那么这个函数被称为凹函数 (concave function)。对应地,也有严格凹函数(strictly concave function)的定义。如果是凸函数,那么就是凹函数。
使用归纳法,我们可以根据公式(1.114)证明凸函数满足
其中,对于任意点集。都有且 。公式(1.115)的结果被称为Jensen不等式(Jensen's inequality)。如果我们把看成取值为的离散变量x的概率分布,那么公式(1.115)就可以写成
其中,表示期望。对于连续变量,Jensen不等式的形式为
我们把公式(1.117)形式的Jensen不等式应用于公式(1.113)给出的Kullback-Leibler散度,可得
推导过程中,我们使用了是凸函数的事实,以及标准化条件。实际上,是严格凸函数,因此只有对于所有x都成立时,等号才成立。因此我们可以把Kullback-Leibler散度看做两个分布和之间不相似程度的度量。
我们看到,在数据压缩和密度估计(即对未知概率分布建模)之间有一种隐含的关系,因为当我们知道真实的概率分布之后,我们可以给出最有效的压缩。如果我们使用了不同于真实分布的概率分布,那么我们一定会损失编码效率,并且在传输时增加的平均额外信息量至少等于两个分布之间的Kullback-Leibler散度。
假设数据通过未知分布生成,我们想要对建模。我们可以试着使用一些参数分布来近似这个分布。由可调节的参数控制(例如一个多元高斯分布)。一种确定的方式是最小化和之间关于的Kullback-Leibler散度。我们不能直接这么做,因为我们不知道。但是,假设我们已经观察到了服从分布p(x)的有限数量的训练点,其中。那么,关于的期望就可以通过这些点的有限加和,使用公式(1.35)来近似,即
右侧的第二项与无关,第一项是使用训练集估计的分布下的的负对数似然函数。因此我们看到,最小化Kullback-Leibler散度等价于最大化似然函数。
现在考虑由给出的两个变量x和y组成的数据集。如果变量的集合是独立的,那么他们的联合分布可以分解为边缘分布的乘积。如果变量不是独立的,那么我们可以通过考察联合概率分布与边缘概率分布乘积之间的Kullback-Leibler散度来判断它们是否“接近”于相互独立。此时,Kullback-Leibler散度为
这被称为变量之间的互信息(mutual information)。根据Kullback-Leibler散度的性质,我们看到,当且仅当相互独立时等号成立。使用概率的加法和乘法规则,我们看到互信息和条件熵之间的关系为
因此我们可以把互信息看成由于知道y值而造成的x的不确定性的减小(反之亦然)。从贝叶斯的观点来看,我们可以把看成的先验概率分布,把看成我们观察到新数据之后的后验概率分布。因此互信息表示一个新的观测引起的x的不确定性的减小。