目前为止,我们假设训练数据点在特征空间中是线性可分的。解得的支持向量机在原始输入空间中会对训练数据进行精确地划分,虽然对应的决策边界是非线性的。然而,在实际中,类条件分布可能重叠,这种情况下对训练数据的精确划分会导致较差的泛化能力。
因此我们需要一种方式修改支持向量机,允许一些训练数据点被误分类。根据式(7.19),我们看到在可以分开的类别的情况下,我们隐式地使用了一个误差函数。当数据点被错误分类时,这个误差函数等于无穷大,而当数据点被正确分类时,这个误差函数等于零,这样就将模型参数优化为了最大化边缘。我们现在修改这种方法,使得数据点允许在边缘边界的“错误侧”,但是增加一个惩罚项,这个惩罚项随着与决策边界的距离的增大而增大。对于接下来的最优化问题,令这个惩罚项是距离的线性函数比较方便。为了完成这一点,我们引入松弛变量(slack variable),其中,每个训练数据点都有一个松弛变量(Bennett, 1992; Cortes and Vapnik, 1995)。对于位于正确的边缘边界内部的点或边界上的点,,对于其它点。因此,对于位于决策边界上的点,,且的点就是被误分类的点。这样,式(7.5)给出的精确分类的限制条件就被替换为
其中松弛变量被限制为满足。的数据点被正确分类,要么位于边缘上,要么在边缘的正确一侧。的点位于边缘内部,但是在决策边界的正确一侧。的点位于决策边界的错误一侧,是被错误分类的点。如图7.3所示。
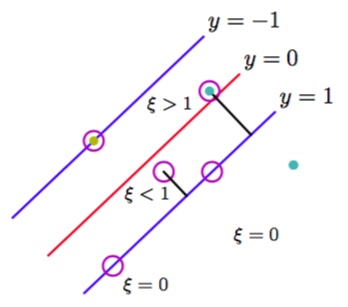
图 7.3 松弛变量的说明。圆圈标记的数据点是支持向量。
这种方法有时被描述成放宽边缘的硬限制,得到一个软边缘(soft margin),并且允许一些训练数据点被错分。注意,虽然松弛变量允许类分布的重叠,但是这个框架对于异常点很敏感,因为误分类的惩罚随着线性增加。
现在我们的目标是最大化边缘,同时以一种比较柔和的方式惩罚位于边缘边界错误一侧的点。于是,我们最小化
其中参数控制了松弛变量惩罚与边缘之间的折中。由于任何被误分类的数据点都有,因此是误分类数据点数量的上界。于是,参数类似于(作用相反的)正则化系数,因为它控制了最小化训练误差与模型复杂度之间的折中。在的期限情况下,我们就回到了之前讨论过的用于线性可分数据的支持向量机。
我们现在想要在式(7.20)以及的条件下最小化公式(7.21)。对应的拉格朗日函数为:
其中和是拉格朗日乘数。对应的KKT条件为
其中。
我们现在对和进行最优化。使用式(7.1)给出的的定义,我们有
使用这些结果,从拉格朗日函数中消去,我们得到形式为
的拉格朗日函数。这与线性可分的情况完全相同,唯一的区别就是限制条件多少有些差异。为了理解这些限制条件究竟是什么,我们注意到,由于是拉格朗日乘数,因此必须有。此外,式(7.31)以及表明。于是,我们关于对偶变量最大化式(7.32)时必须要满足
的限制。其中。式(7.33)被称为盒限制(box constraint)。这又一次变成了一个二次规划的问题。如果我们将式(7.29)代入式(7.1),我们看到对于新数据点的预测又一次使用了式(7.13)。
我们现在可以表示最终的解。同样的,对于数据点的一个子集,有,在这种情况下这些数据点对于预测模型(7.13)没有贡献。剩余的数据点组成了支持向量。这些数据点满足,因此根据式(7.25),它们必须满足
如果,那么式(7.31)表明,根据式(7.28),这要求,从而这些点位于边缘上。的点位于边缘内部,那么,如果则被正确分类,如果则分类错误。
为了确定公式(7.1)中的参数,我们注意到的支持向量满足即,因此满足
与之前一样,一个对于数值计算比较稳定的解可以通过求平均的方式得到,结果为:
其中表示满足的数据点的下标集合。
支持向量机的另一种等价形式,被称为v-SVM,由Scholkopf et al.(2000)提出。它涉及到最小化
限制条件为
这种方法的优点是,参数代替了参数,它既可以被看做边缘错误(margin error)(的点,因此就是位于边缘边界错误一侧的数据点,它可能被误分类也可能没被误分类)的上界,也可以被看做支持向量比例的下界。图7.4给出了v-SVM用于人造数据集的一个例子。
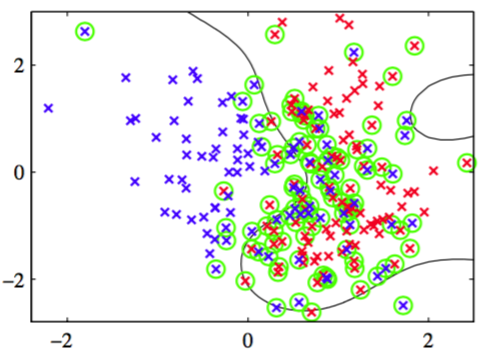
图 7.4 v-SVM应用于二维不可分数据集的例子。圆圈表示支持向量。
这里使用了形如的高斯核,且。
虽然对新输入的预测只通过支持向量完成,但是训练阶段(即确定参数的阶段)使用了整个数据集,因此找到一个解决二次规划问题的高效算法很重要。我们首先注意到由公式(7.10)或式(7.31)给出目标函数是二次的,因此如果限制条件定义了一个凸区域(由于限制条件的线性性质,实际情况确实是这样),那么任意局部最优解也是全局最优解。因为需要的计算量和存储空间都相当大,所以使用传统的方法直接求解二次规划问题通常是不可行的,因此我们需要寻找更实际的方法。分块(chunking)方法(Vapnik, 1992)利用了如果我们将核矩阵中对应于拉格朗日乘数等于零的行和列删除,那么拉格朗日函数是不变的这一事实。这使得完全的二次规划问题被分解为一系列小的二次规划问题,这些小的问题的目标是识别出所有的非零拉格朗日乘数,然后丢弃其它的。分块可以通过保护共轭梯度(protected conjugate gradient)方法实现(Burges, 1998)。虽然分块可以将二次函数中矩阵的大小从数据点的个数的平方减小到近似等于非零拉格朗日乘数的个数的平方,但是对于大规模应用来说,这个数量仍然过大,从而内存无法满足要求。分解方法(decomposition method)(Osuna et al., 1996)也解决一系列较小的二次规划问题,但是这些问题被设计为具有固定的大小,这个方法可以应用于任意规模的数据集。然而,这种方法仍然涉及到二次规划子问题的数值解,求出这些数值解是很困难的,代价很高的。一种最流行的训练支持向量机方法是被称为顺序最小化优化(sequential minimal optimization),或称为SMO(Platt, 1999)。这种方法考虑了分块方法的极限情况,每次只考虑两个拉格朗日乘数。这种情况下,子问题可以解析地求解,因此避免了数值二次规划。选择每一步骤中需要考虑的拉格朗日乘数对时,使用了启发式的方法。在实际应用中,SMO与训练数据点数量的关系位于线性与二次之间,取决于具体的应用。
我们已经看到核函数对应于特征空间中的内积。特征空间可以是高维的,甚至是无穷维的。 通过直接对核函数操作,而不显式地引入特征空间,支持向量机或许在一定程度上避免了维度灾难的问题。然而,因为限制了特征空间维度的特征的值之间存在限制,是哟一事实并非如此。为了说明这一点,考虑一个简单的二阶多项式核,我们可以用它的分量进行展开
于是这个核函数表示六维特征空间中的一个内积,其中输入空间到特征空间的映射由向量函数描述。然而,对这些特征加权的系数被限制为具体的形式。因此,原始二维空间中的任意点集都会被限制到这个六维特征空间中的二维非线性流形中。
我们已经强调,支持向量机不提供概率输出,而是对新的输入进行分类决策,这个事实。Veropoulos et al.(1999)讨论了对SVM的修改,使其能控制假阳性和假阴性之间的权衡。然而,如果我们希望把SVM用作较大的概率系统中的一个模块,那么我们需要对于新的输入的类别标签的概率预测。
为了解决这个问题,Platt(2000)提出了使用logistic sigmoid函数拟合训练过的支持向量机的输出的方法。具体来说,需要求解的条件概率被假设具有
这样的形式,其中由式(7.1)定义。参数的值通过最小化交叉熵误差函数的方式确定。交叉熵误差函数根据由组成的训练数据集定义。为了避免严重的过拟合现象,用于拟合sigmoid函数的数据需要独立于训练原始SVM的数据。这种两个阶段的方法等价于假设支持向量机的输出表示属于类别的的对数概率。由于SVM的训练过程并没有体现这种倾向,因此SVM给出的对后验概率的近似结果比较差(Tipping, 2001)。